
コンテスト概要
小分子 (化学物質) が 3 つの可能性のあるタンパク質ターゲットに結合するかを予測

DNA エンコード化学ライブラリ (DEL) テクノロジを使用して収集された小分子: 1 億 3,300 万個
※Building Blockの組み合わせで、上記の多様性を実現している。そのため、元のBuilding Blockは数1000程で少ない。
対象タンパク質3種:
- EPHX2 (sEH):エポキシド加水分解酵素 2 、高血圧と糖尿病の進行に対する潜在的な薬物ターゲット
- BRD4:ブロモドメイン 4、癌の進行に関与しており、その活性を阻害する薬剤が数多く発見
- ALB(HSA):血清アルブミン、血液中に最も多く含まれるタンパク質であり、体内で候補薬物を吸収し、標的組織から隔離する役割を担うことが多い。候補薬物を調整してアルブミンや他の血液タンパク質との結合を抑えることは、候補薬物の効果を高める戦略である。
タンパク質と小分子の結合を測定:0(非結合), 1(結合)のバイナリ
結合する小分子は、標的タンパク質の活性化を阻害する阻害剤として、薬になる可能性がある。
上記の訓練データから、未知の小分子のテストデータの結合の平均精度を予測
何が起こったか?
最終順位は、312/1946 ぴえん🥺

Private Leaderboard(最終順位)をみると…
※コンペ中は一部の未知データで順位付けされたPublic Leaderboardが公開される。
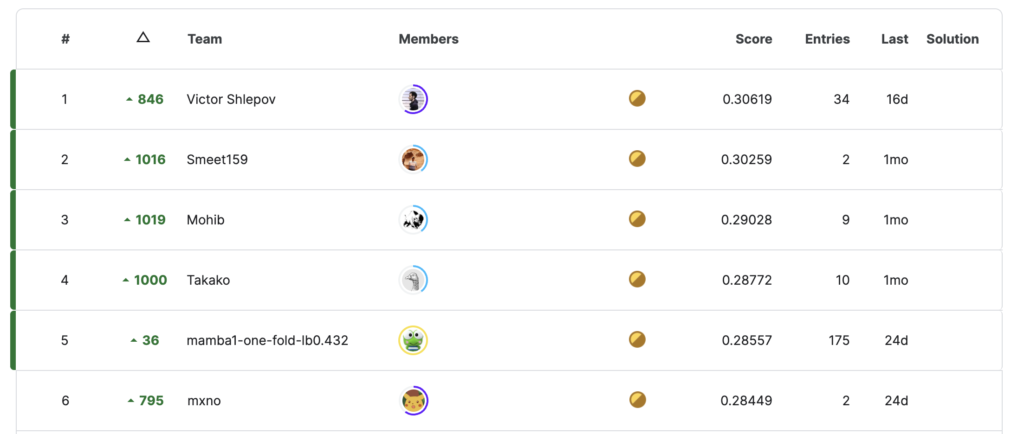
ファ?トップ4人の順位が1000位くらい、上がっている…
全体が1946人なので、偏差値50→80ぐらいの変化?(てきとー)
自分の他の提出結果を見ると…
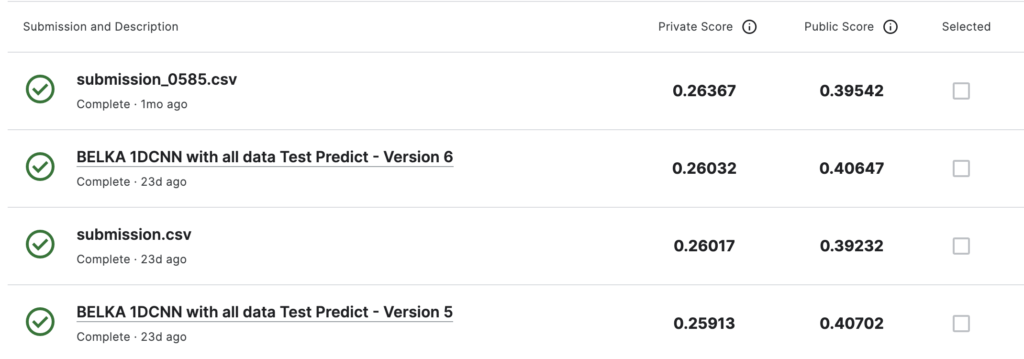
Privete Score 0.26って60-70位で、シルバーメダルやん…
自分が提出していたものは、二つとも複数のモデルをアンサンブル(重み付き和)してPublic Scoreを微調整してあげたもの


対して、Private Scoreが高いのは、単一の1D CNNモデルを15Foldの層状K分割で学習させたもの
おそらく、複数モデルのアンサンブルは、訓練データに過学習しすぎた🥺
まとめ
複数モデルのアンサンブルでPublic Scoreを上げるのは悪くないと思うが過学習に注意
2つを最終提出できるので、アンサンブルと単一モデルの交差検証などに分けて、多様性を持たせよう(一敗)
おまけ

競技中に気になっていたMambaの提出の人の順位があまり変動していない…
汎化性能、高スギィ✌︎(‘ω’✌︎ )
Mambaやれんのか…?



コメント